
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 스마트포인터
- 프레임워크
- thread
- Design Pattern
- 멀티쓰레드
- Atomic
- EFFECTIVE C++
- C
- Unreal
- random access
- 멀티코어
- material
- 옵저버
- observer pattern
- 쓰레드
- multi-core
- vector
- 유니크포인터
- MultiCore
- 게임공학과
- 옵저버 패턴
- sequential
- 메모리관리
- Multithread
- 디자인패턴
- 복사생성자
- 한국산업기술대학교
- 멀티코어 프로그래밍
- stl
- c++
- Today
- Total
태크놀로지
멀티쓰레드 프로그래밍으로 덧셈프로그램 만들기 본문
한국산업기술대학교 게임공학부 정내훈 교수님 멀티코어 2주차 강의
멀티쓰레드 프로그래밍에서 중요한사항
- 올바른 결과가 나와야한다.
- 싱글 쓰레드보다 성능향상이 커야한다.
실습1 - 여러 쓰레드 생성
#include <iostream>
#include <thread>
#include <vector>
using namespace std;
int sum = 0;
void f()
{
for (int i = 0; i < 2500'0000; ++i)
sum += 2;
}
int main()
{
vector<thread> threads;
for (int i = 0; i < 2; ++i)
threads.emplace_back(f);
for (auto& t : threads)
t.join();
cout << "Sum = " << sum << endl;
}
결과가 10000'0000이 나와야하는데 5500만정도 밖에 안나온다. -> Data Race 발생!
오류 발생원인
- 공유 메모리를 여러 쓰레드에서 읽고 쓴다.
- 읽고 쓰는 순서에 따라 실행결과가 달라진다. (예상치 못한 결과발생)
- 이것을 Data Race라고 한다.
※ Data Race 란
- 복수개의 쓰레드가 하나의 메모리에 동시접근
- 적어도 한개는 write (read는 상관없음)
Data Race를 제대로 이해하고 있는가?
1. 앞의 프로그램을 싱글코어에서 동작시키면 결과가 잘나오는가? (X)
- 싱글코어여도 명령어 사이에 컨텍스트 스위칭이 일어나면서 잘못된 결과가 나오게 된다.
2. 앞의 프로그램을 "sum+=2"(어셈블리 명령어 3개)를 "_asm add sum,2"(명령어 하나) 로 바꾸면? (X)
- 명령어는 마이크로코드로 실행되는데, 마이크로코드가 읽고 더하고 쓰고를 한 클럭에 실행하지 않는다. 따라서 코어랑 작동방식이 동일하다. 즉 기계어가 Data Race를 일으키나, 마이크로코드가 일으키나 동일함.
3."_asm add sum, 2"로 바꾼 후 싱글코어에서 동작시키면 올바른 결과가 나오는가? (O)
- 항상 올바른 결과가 나온다. 컨텍스트스위칭은 운영체제가 실행되는 프로세스를 바꾸는것이다. 코드 내에서 컨텍스트스위칭하는 코드가 없기 때문에 올바른 결과가 나온다.
- 컨텍스트스위칭이 일어나려면 운영체제가 실행되어야하고 운영체제는 인터럽트가 실행한다. (명령어 실행중에는 인터럽트 처리를 절대하지 않음!)
실습1 해결방법
- Data Race를 없애면 된다.
어떻게?
- Lock과 Unlock을 사용한다.
- 복수개의 쓰레드가 동시에 접근할 수 없도록 한다.
Lock과 Unlock의 주의점
- Mutex객체는 전역변수로 설정해주어야한다. (지역변수 선언시 해당쓰레드에서만 작동함.)
- 같은 객체 사이에서만 Lock/Unlock이 동작
- 다른 Mutex객체는 상대방을 모름
- 서로 동시에 실행되어도 괜찮은 Critical Section이 있다면 다른 Mutex객체로 보호하는것이 성능이 좋음.
- 같은 Mutex객체로 보호하면 동시에 실행이 안됨
Mutex 객체가 필요한 이유

- sum += 2; 와 sum *=3;은 sum이라는 같은 공유자원을 사용하기 때문에 a뮤텍스를 사용하여 동시에 실행안되도록 설정
- sum과 counter는 상관없는 친구기 때문에 b뮤텍스를 사용하여 분리한다. (이중락킹 -> 이중락킹시 데드락현상이 발생할 수 있다.)
실습2 - mutex를 사용하여 lock / unlock 사용
int sum = 0;
mutex sum_lock;
void f()
{
for (int i = 0; i < 2500'0000; ++i)
{
// lock의 비중을 줄여줘야한다.
sum_lock.lock();
sum += 2;
sum_lock.unlock();
}
}원인은 해결되지만 너무느림. lock 사용시 거의 몇 백배 느려짐.
쓰레드 개수에 따른 실행시간 비교 (디버그모드가 아닌 릴리즈모드에서 성능을 측정해보자)
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
#include <atomic>
#include <chrono>
using namespace std;
using namespace chrono;
// 강제로 최적화를 막아놓음
volatile int sum = 0;
mutex sum_lock;
void f(int num_thread)
{
// 성능측정을 위해 volatile 사용
for (int i = 0; i < 500'0000 / num_thread; ++i)
{
sum_lock.lock();
sum += 2;
sum_lock.unlock();
}
}
int main()
{
for (int count = 1; count <= 16; count *= 2)
{
vector<thread> threads;
sum = 0;
auto start_t = high_resolution_clock::now();
for (int i = 0; i < count; ++i)
threads.emplace_back(f, count);
for (auto& t : threads)
t.join();
auto end_t = high_resolution_clock::now();
auto exec_time = end_t - start_t;
cout << "Number of threads = " << count << ", ";
cout << "Exec Time = " << duration_cast<milliseconds>(exec_time).count() << "ms , ";
cout << "Sum = " << sum << endl;
}
}- Lock (O/X)
- Volatile로 릴리즈모드 자동 최적화 기능을 막고 성능측정을 해보자.
Lock 했을때의 실행결과

정확한 결과는 나오지만, 성능이 오히려 싱글코어보다 떨어진다.
Lock을 안했을때의 실행결과

속도는 줄었지만 별로 큰 차이도 안나고, 싱글코어 이외에 정확한 결과도 나오지 않는다.
Mutex의 lock()은?
- 한번에 하나의 쓰레드만 실행시킴
- 병렬성 감소, 병렬실행으로 인한 성능향상감소
- Lock을 얻지 못하면 Queue에 순서를 저장하고 스핀
- Lock() 메소드 자체의 오버헤드
- 심각한 성능 저하
실습2 해결방법은?
- Lock을 쓰지 않으면 된다.
- "Sum += 2"를 하는 동안 다른 쓰레드가 실행되지 못하도록 하면된다. (lock 없이)
어떻게?
- X86 어셈블리 언어의 "lock" prefic을 사용하여 "sum += 2"를 atomic하게 실행시킨다.
- _asm lock add sum, 2;
- 함수를 데이터레이스 없이 실행하는 것을 atomic이라고 부름
실습3 - lock을 사용하지 않고 Atomic을 사용하자.
atomic<int> sum = 0;
void f(int num_thread)
{
// 성능측정을 위해 volatile 사용
for (int i = 0; i < 5000'0000 / num_thread; ++i)
{
//sum_lock.lock();
sum += 2;
//sum_lock.unlock();
}
}※ Atoimic이란
- 모든 Atomic연산은 다른 Atomic 연산과 동시에 수행되지 않는다. (동시에 실행되니까 Data Race가 발생)
- Atomic 연산은 이전의 명령어의 실행이 모두 끝날 때까지 시작되지 않는다. (순서대로 실행된다.)
- Atomic 연산 이후 명령어는 Atomic연산이 완전히 종료된후에 시작된다.
- 모든 Atomic 연산의 실행순서는 모든 쓰레드에서 동일하게 관찰된다.
※ Atomic과 Volatile의 차이

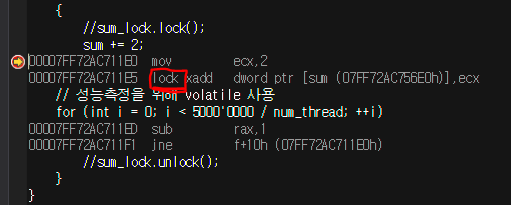
- Release모드시 Volatile은 자동최적화를 강제로 막아주는 역할을 하고, Atomic은 어셈블리에서 연산을 lock해준다.
- Atomic이 Volatile보다 한단계 높은 단계(+lock까지 해줌)이다.
- sum = sum +2;와 sum += 2;와 결과가 다르다. (sum = sum+2 일때 제대로된 결과가 나오지 않는다.)
- sum = sum + 2; 일때 atoic하게 읽고 atomic하게 쓰려해서 그 사이에 다른연산이 일어날 수 있다.
실습3 결과

lock보다 오버헤드가 줄어들어서 성능은 좋아졌지만 여전히 싱글쓰레드보다 느리다.
실습3 해결방법은?
- 처음부터 Data Race가 적도록 프로그램을 재작성하는것이 좋다.
- lock이나 atomic연산 개수를 줄일 수 있다.
- 하지만 lock이나 atomic연산을 완전히 없애는 것은 불가능하다.
실습4 - Data Race가 적도록 재작성한 프로그램
void f(int num_thread)
{
volatile int local_sum = 0;
for (int i = 0; i < 500'0000 / num_thread; ++i) local_sum += 2;
sum_lock.lock();
sum += local_sum;
sum_lock.unlock();
}
로컬변수를 사용해서 한꺼번에 연산된 값을 더해준다.
실행결과

- 하이퍼쓰레드로 인한 성능향상이 하나도 없다.
- 코어개수만큼 정직한 성능결과가 나온다.
출처
한국산업기술대학교 게임공학부 정내훈 교수님 강의 - 멀티코어 프로그래밍
'멀티코어' 카테고리의 다른 글
| 멀티쓰레드 프로그래밍은 어디서 사용되고 있는가? (0) | 2020.09.13 |
|---|---|
| 멀티쓰레드 프로그래밍으로 덧셈프로그램 만들기 (이외 방법) (0) | 2020.09.13 |
| 멀티코어 하드웨어 소개 (0) | 2020.09.04 |
| 멀티코어 프로그래밍에서의 쓰레드와 프로세스의 관계 (0) | 2020.09.02 |
| 멀티코어 프로그래밍 개요 & 병렬컴퓨터 (0) | 2020.09.02 |

