
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 게임공학과
- Unreal
- Design Pattern
- 스마트포인터
- 디자인패턴
- vector
- 멀티코어 프로그래밍
- random access
- 프레임워크
- 쓰레드
- C
- observer pattern
- thread
- 유니크포인터
- 멀티코어
- MultiCore
- 메모리관리
- EFFECTIVE C++
- Atomic
- material
- 복사생성자
- Multithread
- c++
- 옵저버
- 옵저버 패턴
- stl
- multi-core
- 멀티쓰레드
- sequential
- 한국산업기술대학교
- Today
- Total
태크놀로지
[실습1] 베이커리 알고리즘 본문
베이커리 알고리즘 이론 & 원리
en.wikipedia.org/wiki/Lamport%27s_bakery_algorithm
Lamport's bakery algorithm - Wikipedia
Lamport's bakery algorithm is a computer algorithm devised by computer scientist Leslie Lamport, as part of his long study of the formal correctness of concurrent systems, which is intended to improve the safety in the usage of shared resources among multi
en.wikipedia.org
위를 참고해서 베이커리 알고리즘을 구현하였습니다.
베이커리 알고리즘은 Data Race 방지를 위해 설계된 상호배제 알고리즘 중 하나입니다. Bakery algorithm은 빵집을 비유로 고객들에게 번호표를 부여하여, 번호표를 기준으로 먼저 처리해야할 일들의 우선순위를 부여하는 알고리즘입니다.
모든 고객들은 맨처음 번호표를 부여받습니다. 그리고 자기 순서가 올때까지 대기합니다. 이로서 두 명 이상의 클라이언트들이 공유자원에 접근하지 못하도록 합니다.
※ 번호표는 클라이언트의 쓰레드 우선순위값입니다. 번호표 값이 낮을 수록 우선적으로 쓰레드가 critical section에 접근하게 됩니다.
알고리즘의 구현 - 수도코드 분석
// declaration and initial values of global variables
Entering: array [1..NUM_THREADS] of bool = {false};
Number: array [1..NUM_THREADS] of integer = {0};
lock(integer i) {
Entering[i] = true;
Number[i] = 1 + max(Number[1], ..., Number[NUM_THREADS]);
Entering[i] = false;
for (integer j = 1; j <= NUM_THREADS; j++) {
// Wait until thread j receives its number:
while (Entering[j]) { /* nothing */ }
// Wait until all threads with smaller numbers or with the same
// number, but with higher priority, finish their work:
while ((Number[j] != 0) && ((Number[j], j) < (Number[i], i))) { /* nothing */ }
}
}
unlock(integer i) {
Number[i] = 0;
}
Thread(integer i) {
while (true) {
lock(i);
// The critical section goes here...
unlock(i);
// non-critical section...
}
}lock함수 호출시, 클라이언트들은 자신이 번호표를 받기 시작했다라는것을 알리기 위해, label값을 true로 변경합니다. 그리고 현재 존재하는 번호표중 최대값의 1을 더해주어 자신의 번호표가 제일 나중에 뽑았다는것을 나타냅니다.
그리고 다른 클라이언트들이 번호표를 뽑고 있는중인지?를 우선 체크하고, 다른 클라이언트들과 번호표를 비교하여 대기 후 내 차례가 되었을때 critical section에 접근하게 됩니다.
실습 - 베이커리 알고리즘을 사용하여 lock & unlock 기능 구현
#include <iostream>
#include <thread>
#include <vector>
#include <chrono>
#include <mutex>
#include <algorithm>
#include <atomic>
using namespace std;
using namespace chrono;
constexpr int MAX_THREAD = 16;
volatile int g_Sum;
mutex sum_lock;
atomic_bool* g_Flag;
atomic_int* g_Label;
int Max(int thread_num)
{
int maximum = g_Label[0];
for (int i = 0; i < thread_num; ++i)
{
if (maximum < g_Label[i])
maximum = g_Label[i];
}
return maximum;
}
int Compare(int i, int myId)
{
if (g_Label[i] < g_Label[myId]) return 1; // 대기
else if (g_Label[i] > g_Label[myId]) return 0; // 패스
else
{
// 두 번호가 같을경우
if (i < myId) return 1;
else if (i > myId) return 0;
else return 0;
}
}
void b_lock(int myId, int thread_num)
{
// 번호표 받을 준비
g_Flag[myId] = true;
// 다음 번호를 받음
g_Label[myId] = Max(thread_num) + 1;
g_Flag[myId] = false;
// 모든 프로세스에 대한 번호표 비교루프
for (int i = 0; i < thread_num; ++i)
{
while (g_Flag[i]); // 티켓을 받았는지 검사함
while ((g_Label[i] != 0) && Compare(i, myId));
}
}
void b_unlock(int myId)
{
//cout << " complete " << endl;
g_Label[myId] = 0;
}
void Process(int my_Id, int num_thread)
{
for (int i = 0; i < 10000'0000 / num_thread; ++i) {
//sum_lock.lock();
//sum_lock.unlock();
//b_lock(my_Id,num_thread);
g_Sum += 1;
//b_unlock(my_Id);
}
}
int main(void)
{
for (int count = 1; count <= MAX_THREAD; count *= 2)
{
vector<thread> threads;
// 변수 초기화
g_Flag = new atomic_bool[count];
g_Label = new atomic_int[count];
for (int i = 0; i < count; ++i)
{
g_Label[i] = 0;
g_Flag[i] = false;
}
g_Sum = 0;
auto start_t = high_resolution_clock::now();
for (int i = 0; i < count; ++i)
threads.emplace_back(Process, i, count);
for (auto& t : threads) t.join();
auto end_t = high_resolution_clock::now();
auto exec_time = end_t - start_t;
cout << "Number of threads = " << count << ", ";
cout << "Exec Time = " << duration_cast<milliseconds>(exec_time).count() << "ms , ";
cout << "Sum = " << g_Sum << endl;
}
}
결과창

쓰레드 개수가 16개일때는 너무 많은 시간이 소요되어, 출력창에 표시하지 못하였습니다.
Bakery Algorithm 로직 오류 예측
출력창에서는 정확한 결과가 나왔지만, 무조건 정확한 결과가 나올것이라는것을 보장하기는 힘듭니다.
Case 1 - Critical Section에서 연산이 끝난후 Flag 변경
void b_lock(int myId, int thread_num)
{
// 번호표 받을 준비
g_Flag[myId] = true;
// 다음 번호를 받음
g_Label[myId] = Max(thread_num) + 1;
// g_Flag[myId] = false; -> unlock으로 이동
// 모든 프로세스에 대한 번호표 비교루프
for (int i = 0; i < thread_num; ++i)
{
while (g_Flag[i]); // 티켓을 받았는지 검사함
while ((g_Label[i] != 0) && Compare(i, myId));
}
}
void b_unlock(int myId)
{
//cout << " complete " << endl;
g_Flag[myId] = false;
g_Label[myId] = 0;
}위 경우 쓰레드가 동시에 접근하게 될 경우 데드락에 빠지게 됩니다.
-> while (g_Flag[i]) 에서 데드락 발생
Case 2 - Volatile 사용과 메모리 일관성을 위해 번호표를 받는 부분에 atomic fence 사용
void b_lock(int myId, int thread_num)
{
// 번호표 받을 준비
g_Flag[myId] = true;
// 다음 번호를 받음
g_Label[myId] = Max(thread_num) + 1;
g_Flag[myId] = false; -> unlock으로 이동
// atomic fence 번호표를 받기 전까지 메모리 일관성 유지
atomic_thread_fence(std::memory_order_seq_cst);
// 모든 프로세스에 대한 번호표 비교루프
for (int i = 0; i < thread_num; ++i)
{
while (g_Flag[i]); // 티켓을 받았는지 검사함
while ((g_Label[i] != 0) && Compare(i, myId));
}
}
void b_unlock(int myId)
{
//cout << " complete " << endl;
g_Label[myId] = 0;
}싱글쓰레드를 제외하고 정확한 결과가 나오지 않음. 예측하는 바로서 번호표를 받을때까지 메모리 일관성이 유지된다고 해도 티켓을 받았는지 검사하는 대기 루프(while(g_Flag[i]))를 통과한 후에 번호표를 비교할때, 다른 쓰레드에서 번호표를 받게 된다면 정확한 결과가 나올확률이 매우 줄어들게된다고 예측됩니다.
Case 3 - volatile 대신 atomic 변수를 사용
atomic 변수를 사용하므로 변수에 대한 모든 메모리 일관성을 유지합니다. 이로서 volatile과 atomic_fence를 사용했을때 보다 더 정확한 결과가 나오게 됩니다. 하지만 모든 부분을 atomic lock이 실행됨으로 매우 오랜시간이 소요되고, 심지어 코어수가 늘어날수록 정확한 결과가 나오지 않을 확률이 증가합니다.
이는 동시접근에 대한 알고리즘 대처가 부족하다고 판단이 되고, 잘못된 알고리즘이라고 예측됩니다.
std::mutex대신 Bakery Algorithm을 사용할 수 있을까

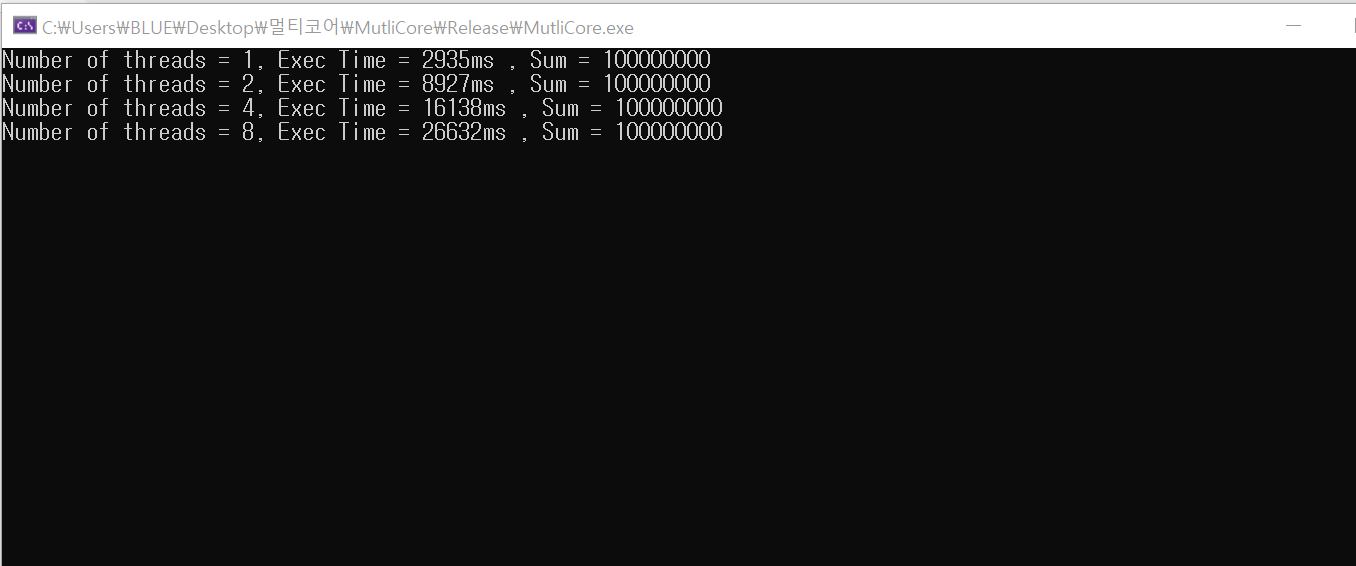
mutex와 비교시 싱글코어에서는 bakery algorithm이 3배 빠른 결과를 보여줍니다. 하지만 코어개수가 늘어날수록 속도 측면이나 정확성 측면에서 매우 약한 모습을 보여주고 있습니다.
결론
std::mutex를 사용하자
'멀티코어' 카테고리의 다른 글
| 동기화 연산과 CAS (0) | 2020.11.03 |
|---|---|
| 메모리 일관성, CPU 메모리 접근방식 (0) | 2020.09.23 |
| 멀티쓰레드 프로그램 작성시 주의해야할점 - CPU (0) | 2020.09.17 |
| 멀티쓰레드 프로그램 작성시 주의해야할점 - 컴파일러 (0) | 2020.09.16 |
| 멀티쓰레드 프로그래밍은 어디서 사용되고 있는가? (0) | 2020.09.13 |


